Semi-transparency in Stata graphics
With version 15, Stata has acquired a graphics feature that lots of people have been asking for over many years: semi-transparency.
Any time you have lines or markers piled up on top of one another, it's impossible to see how many there are. Some are obscured behind others. Semi-transparency fixes this problem by making the line, marker, or whatever, less than completely opaque. Where you would normally specify a colour like mcolor(navy), you can now give it a certain % of opacity, along the scale from 0% (completely transparent: invisible!) to 100% (completely opaque, the default).
Let's try this out with Fisher's irises. We know that the flowers are measured in this dataset in millimeters, and some flowers have exactly the same sizes to the millimeter.
webuse iris, clear
scatter seplen sepwid, mcolor(navy)
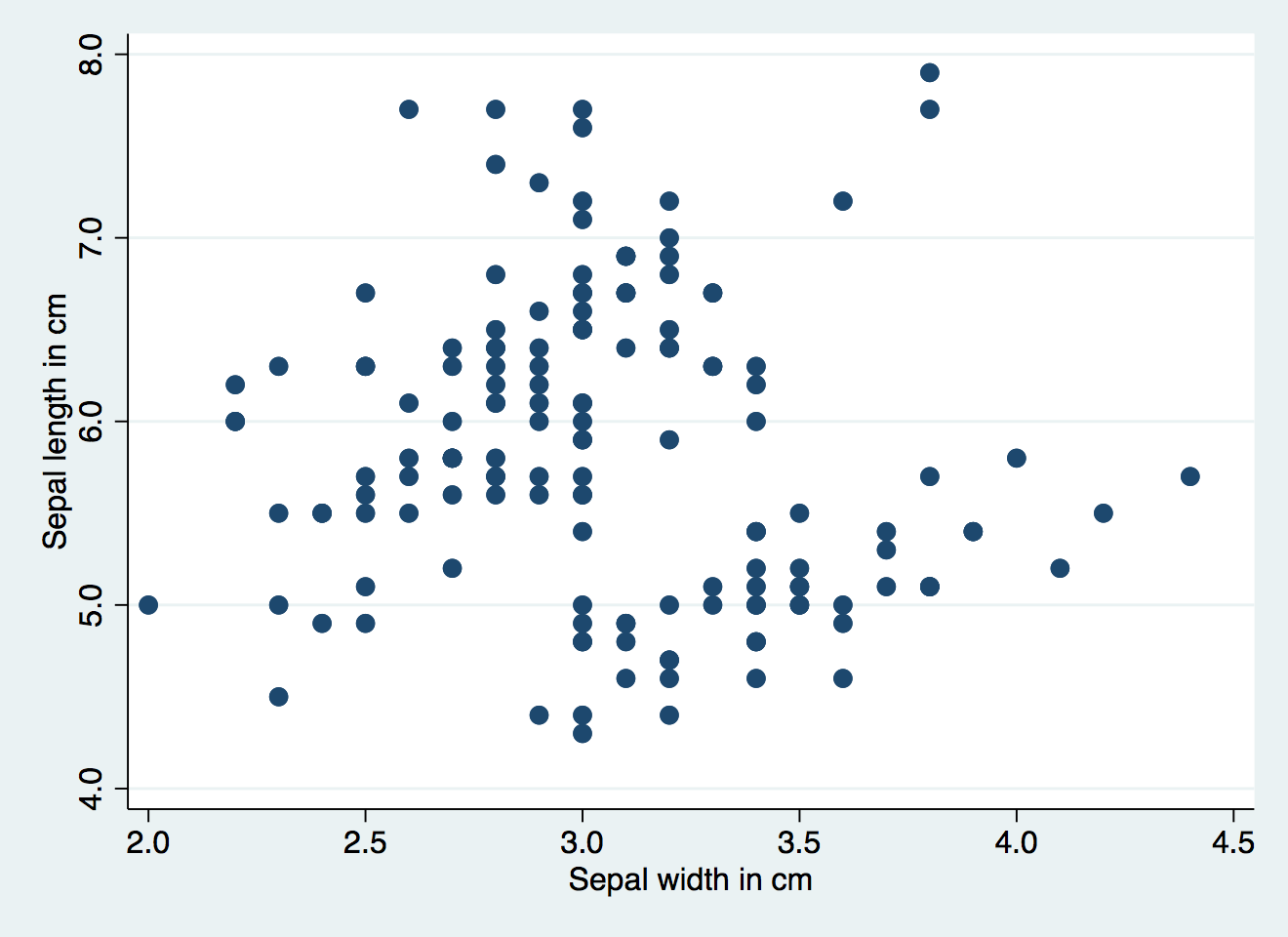
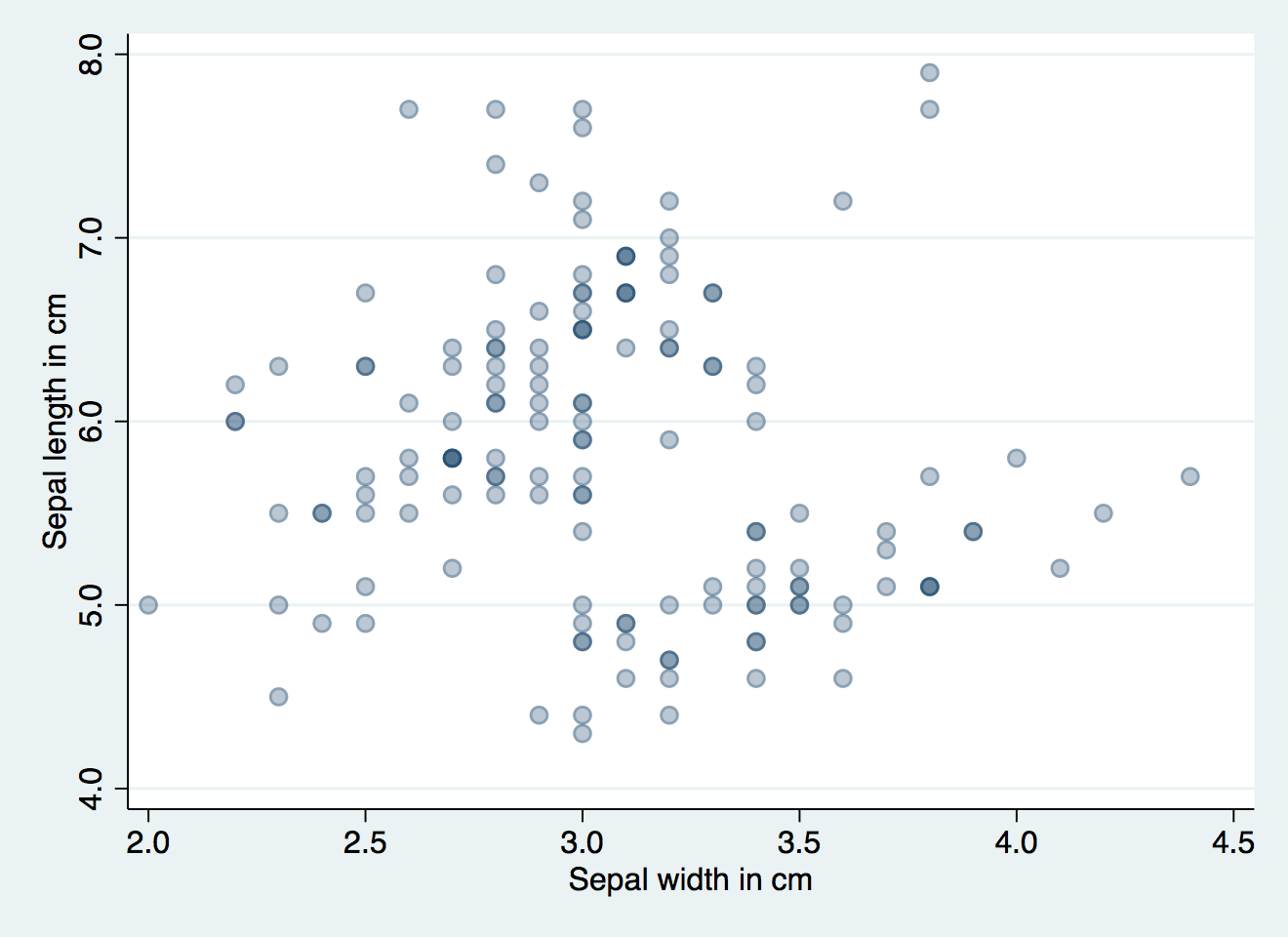
Some of those dots have more than one flower, but which ones? Let's set the markers to 30% opacity:
scatter seplen sepwid, mcolor(navy%30)
It's as simple as that. We just add %30 to the end of whatever colour we are specifying. It works for unnamed colours too, such as those you specify with RGB or CMYK codes. A nice blue, for example, is obtained with RGB 38, 70, 156. That just means red value of 38, green value of 70, blue value of 156 (with maximum value of 255 in each colour). In Stata you would specify it like this: scatter seplen sepwid, mcolor("38 70 156") and to get transparency would just be: scatter seplen sepwid, mcolor("38 70 156 %30"). For RGB and CMYK, you should put double quotes around the codes, and the opacity value inside them too, and once you've done that you can have a space before the percentage sign if you prefer.
Now we can see that some of the combinations of values appear more than once in the data, like the width of 3.8cm and length of 5.1cm. These markers look darker because there are more markers behind, showing through. This visualisation trick works well because it looks very physical, like objects piled up in real life, and it makes it easy for the reader's brain to distinguish the patterns.
Another really valuable use if where you have multiple lines, especially if these are smooth. What appears to be indecipherable spaghetti with 100% opacity can be mentally pulled apart with a lower opacity value. Here's a file with 100 simulated hurricane paths. Once you have downloaded it, we can try plotting them simply:
use "hurricane_paths.dta", clear
line y x, connect(ascending) lcolor(navy)
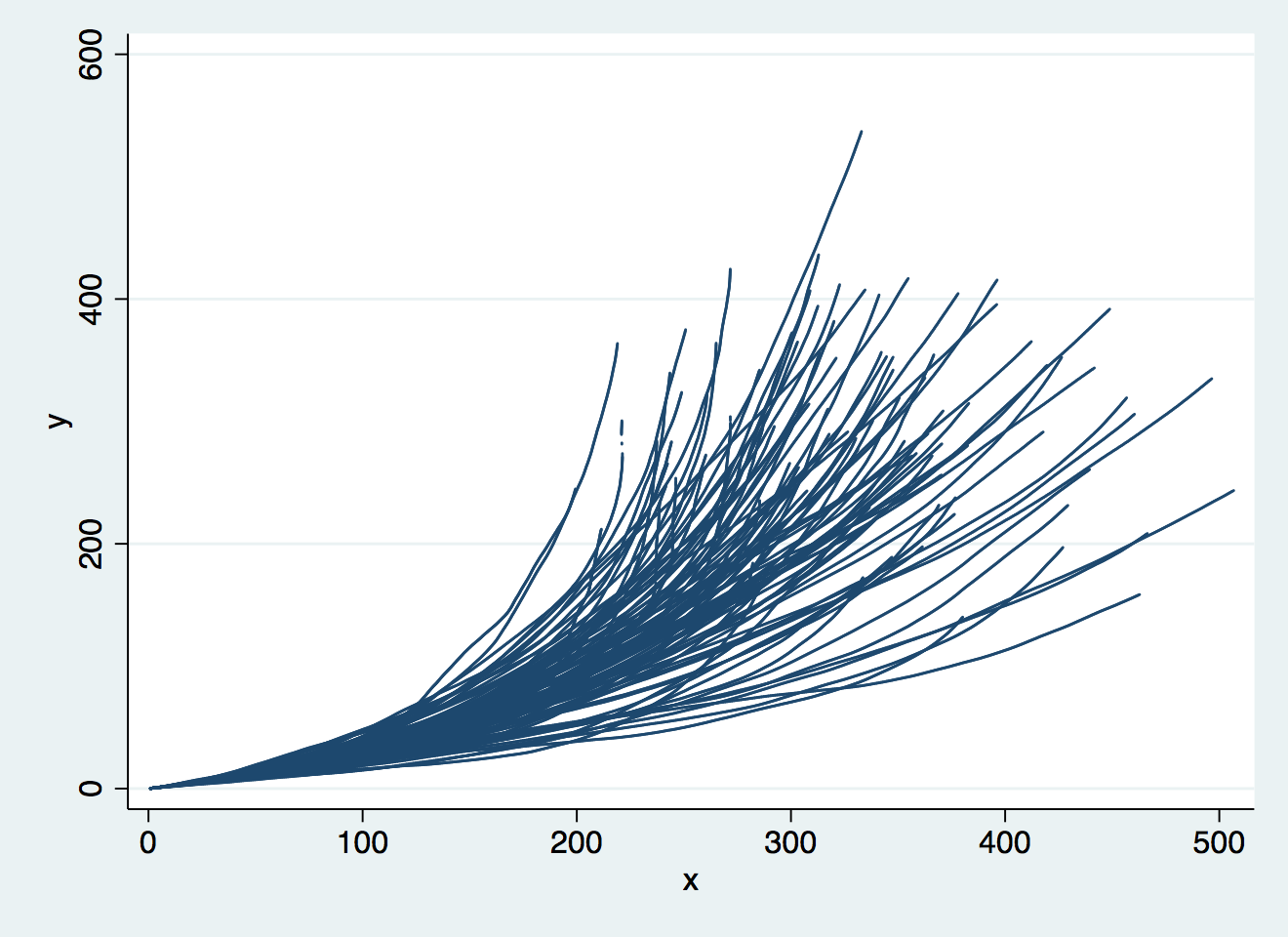
Here, the graph does not make a good tool for forecasting risk from this hurricane, because it's impossible to see how many lines pass near a given point, once the image is saturated with navy blue. The same applies to lots of time series data in line charts, but a very low opacity helps (here 5%):
line y x, connect(ascending) lcolor(navy%5)
Now we can see that the paths fan out quite evenly and there is no particularly high risk area to the right of x=150.
The marker outline: something you never had to think about before
Take a look back at the scatter plot with semi-transparent markers and you might notice that the markers which were solid circles now have a faint but quite noticeable outline. When you draw a marker, Stata is creating the shape with two parts: the outline and the fill. When they are completely opaque, it doesn't matter, but when they are semi-transparewnt, it shows up. You might not want the outline to appear at all; here's three tricks to get rid of it.
The help page for marker options (help scatter##marker_options) tells us about options to do with the outline, which you probably never looked at before. So, to make it disappear, we can make the outline a line of width "none":
mlwidth(none)
or make it have a completely transparent color:
mlcolor(navy%0)
or make it appear on the outside of the marker:
mlalign(outside)
However, the last of these will make the markers slightly larger than before.
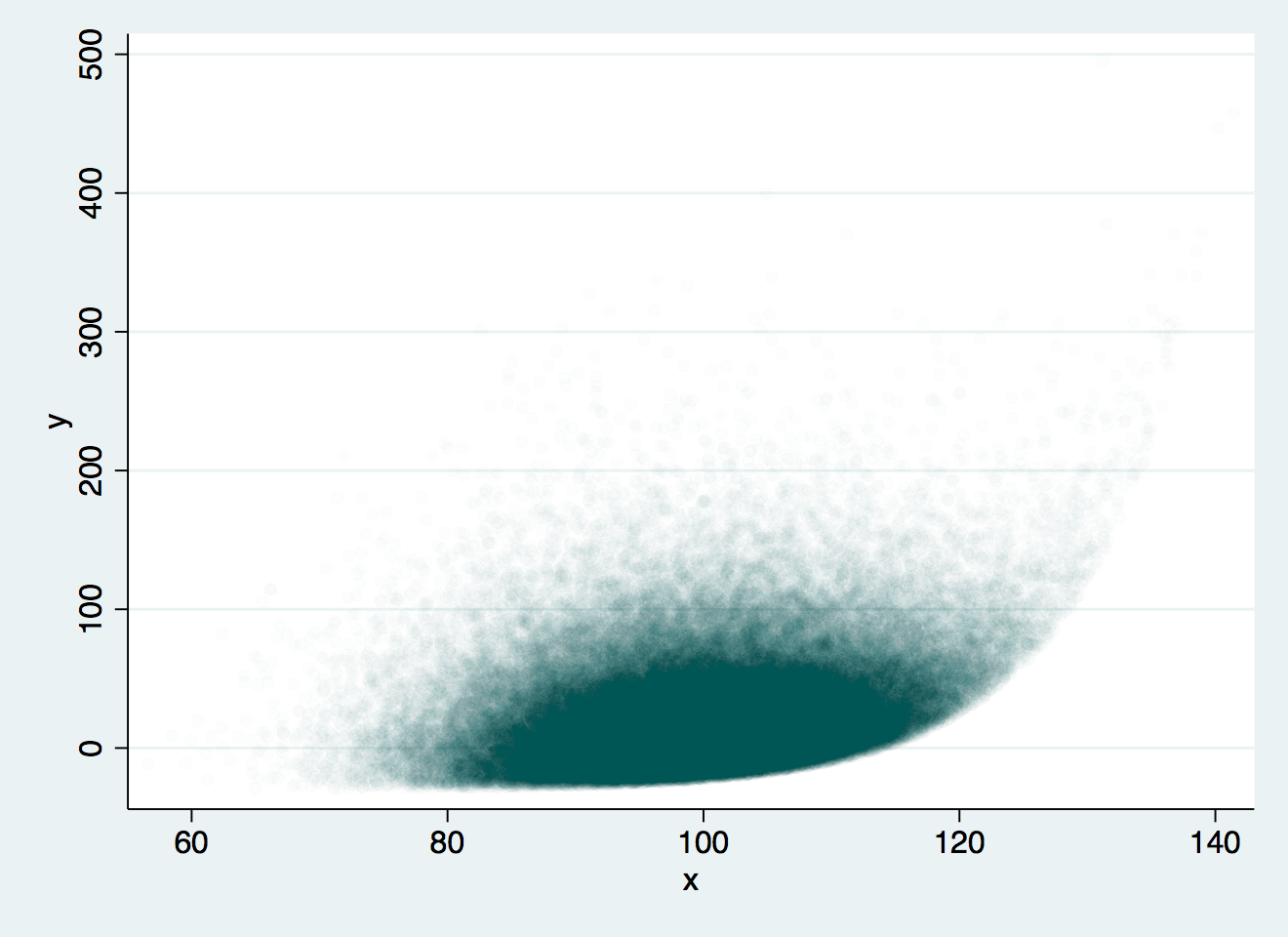
Without outlines, the new semi-transparent scatter plot can be a very effective way of showing a two-dimensional distribution. This will create a strangely-distributed set of 100,000 observations:
clear
set seed 678
set obs 100000
generate x = rnormal(100,10)
generate y = exp((x/10)-8)+((15*rchi2(3))-3)
The standard scatter plot is of no use here:
scatter y x, mcolor(navy)
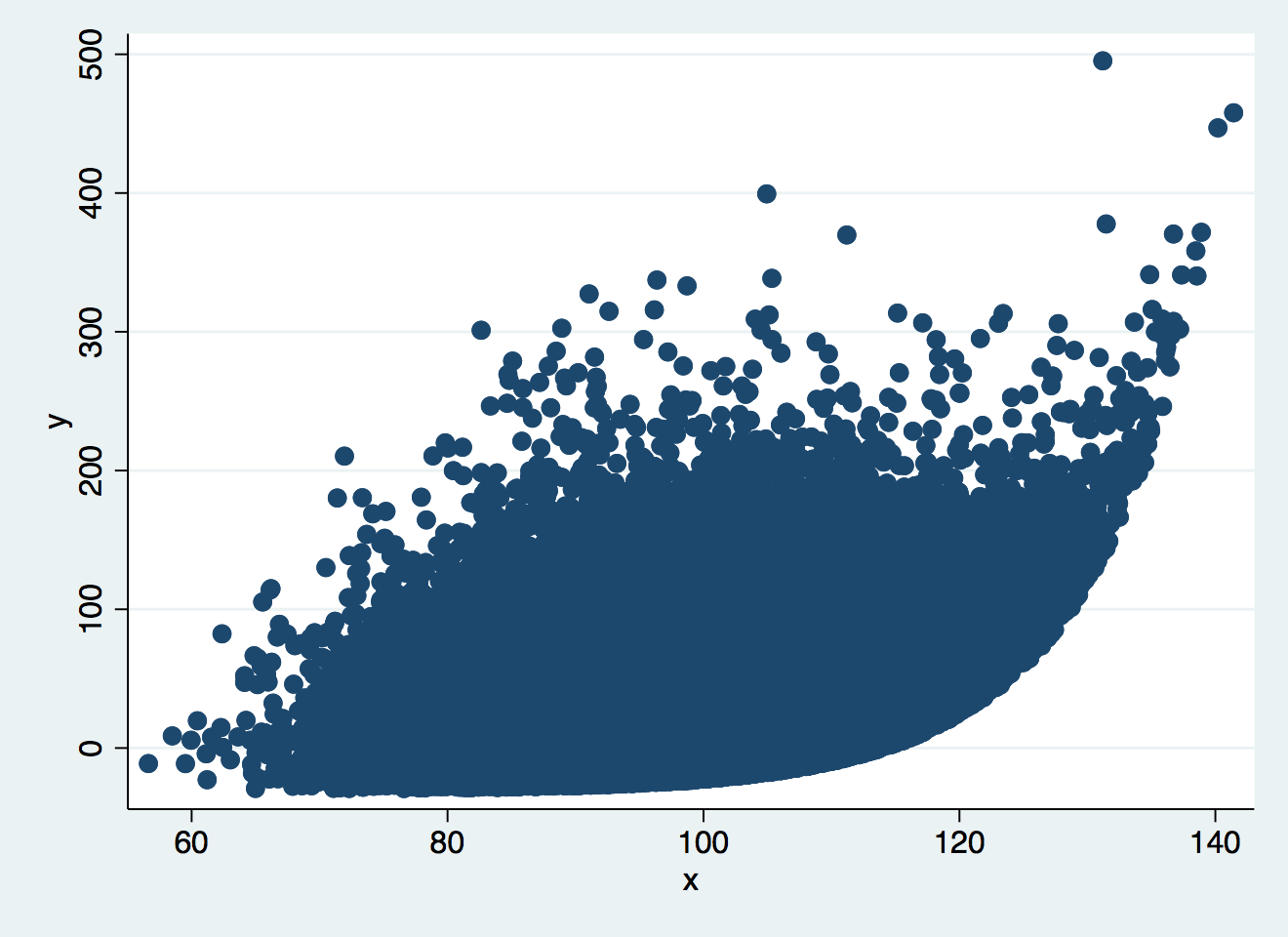
But making the markers small, eliminating the outline, and taking opacity down to the minimum of 1% shows where the bulk of the data lies:
scatter y x, mcolor(navy%1) msize(small) mlwidth(none)
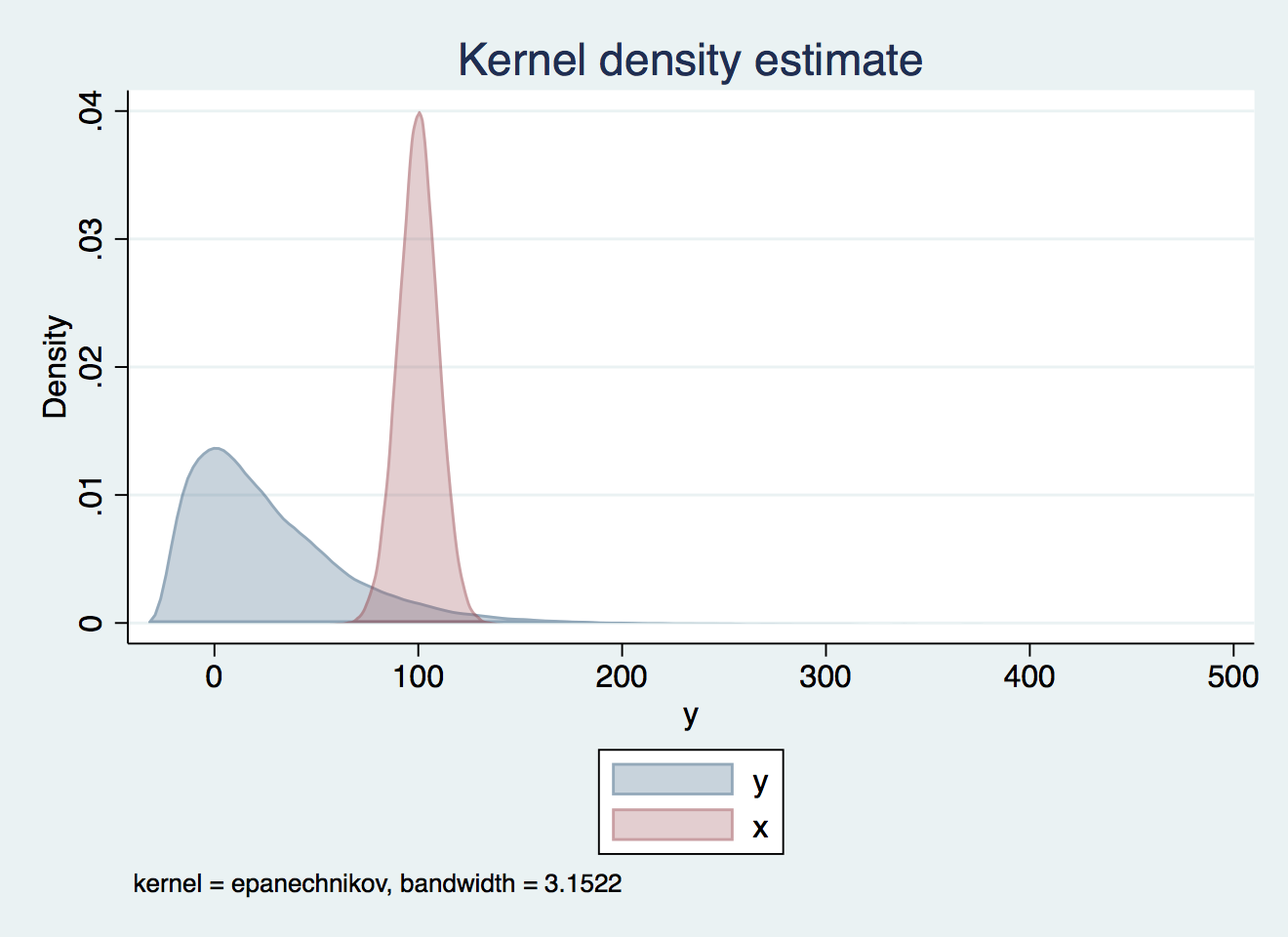
Kernel densities and more
Whereas previously, superimposing density plots and the like involved some compromise as colours disappeared behind one another, this popular look is now easy to achieve:
kdensity y, n(200) color(%30) recast(area) ///
addplot(kdensity x, n(200) color(%30) recast(area)) ///
legend(order(1 "y" 2 "x"))